
QuentinFuxa/WhisperLiveKit
WhisperLiveKit
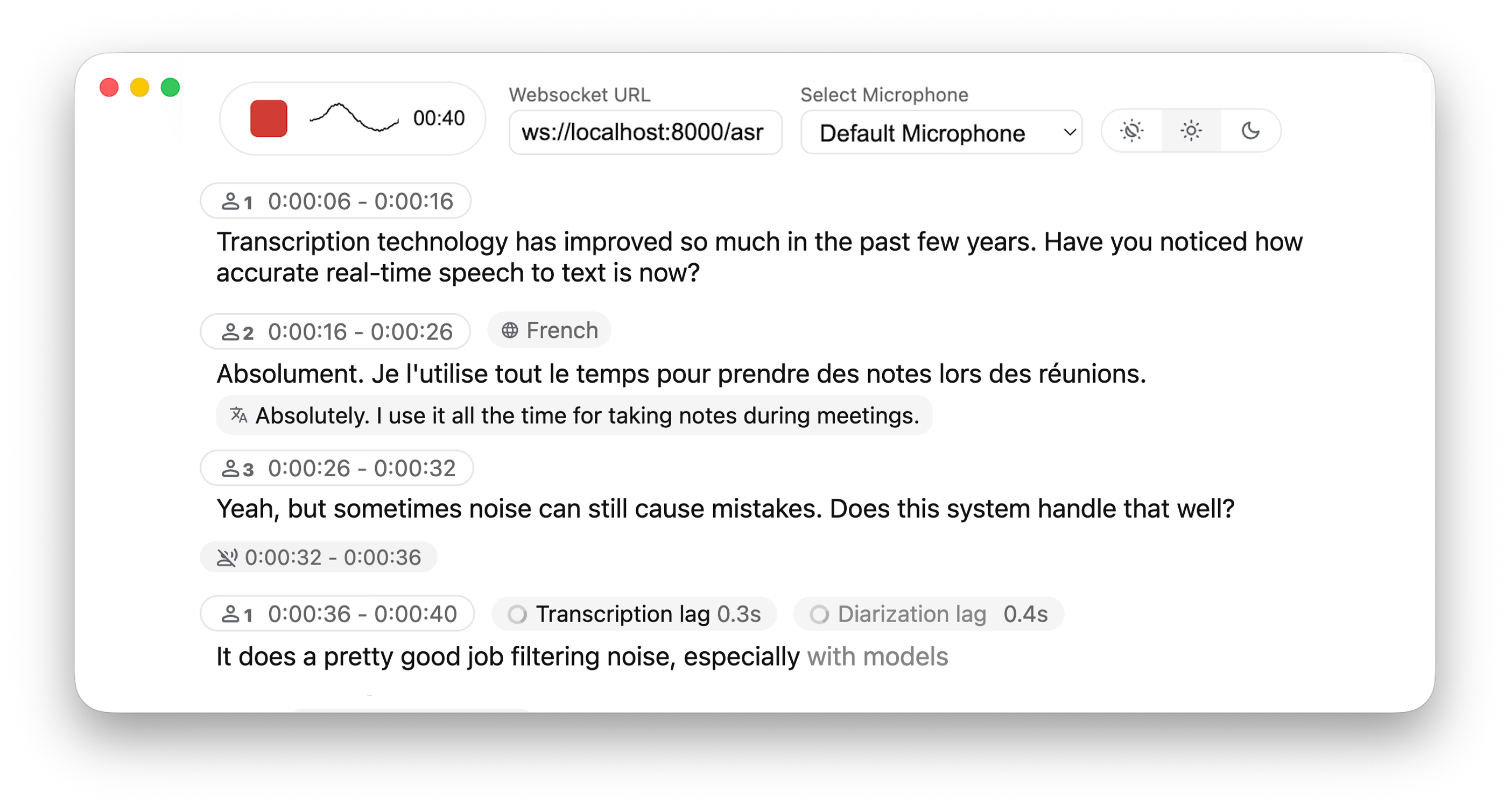
Real-time, Fully Local Speech-to-Text with Speaker Identification

Real-time speech transcription directly to your browser, with a ready-to-use backend+server and a simple frontend. ✨
Powered by Leading Research:
- SimulStreaming (SOTA 2025) - Ultra-low latency transcription with AlignAtt policy
- WhisperStreaming (SOTA 2023) - Low latency transcription with LocalAgreement policy
- Streaming Sortformer (SOTA 2025) - Advanced real-time speaker diarization
- Diart (SOTA 2021) - Real-time speaker diarization
- Silero VAD (2024) - Enterprise-grade Voice Activity Detection
Why not just run a simple Whisper model on every audio batch? Whisper is designed for complete utterances, not real-time chunks. Processing small segments loses context, cuts off words mid-syllable, and produces poor transcription. WhisperLiveKit uses state-of-the-art simultaneous speech research for intelligent buffering and incremental processing.
Architecture
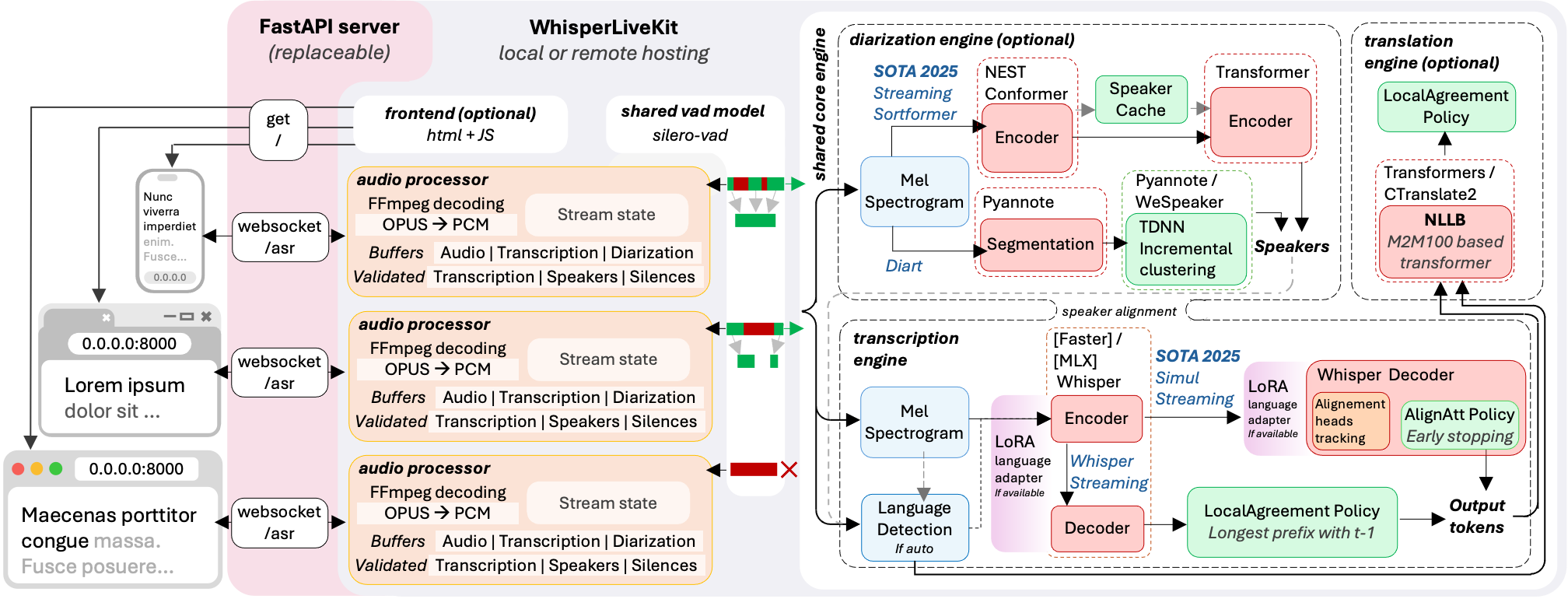
The backend supports multiple concurrent users. Voice Activity Detection reduces overhead when no voice is detected.
Installation & Quick Start
|
|
FFmpeg is required and must be installed before using WhisperLiveKit
OS How to install Ubuntu/Debian sudo apt install ffmpegMacOS brew install ffmpegWindows Download .exe from https://ffmpeg.org/download.html and add to PATH
Quick Start
-
Start the transcription server:
1whisperlivekit-server --model base --language en -
Open your browser and navigate to
http://localhost:8000. Start speaking and watch your words appear in real-time!
- See tokenizer.py for the list of all available languages.
- For HTTPS requirements, see the Parameters section for SSL configuration options.
Optional Dependencies
| Optional | pip install |
|---|---|
| Speaker diarization with Sortformer | git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr] |
| Speaker diarization with Diart | diart |
| Original Whisper backend | whisper |
| Improved timestamps backend | whisper-timestamped |
| Apple Silicon optimization backend | mlx-whisper |
| OpenAI API backend | openai |
See Parameters & Configuration below on how to use them.
Usage Examples
Command-line Interface: Start the transcription server with various options:
|
|
Python API Integration: Check basic_server for a more complete example of how to use the functions and classes.
|
|
Frontend Implementation: The package includes an HTML/JavaScript implementation here. You can also import it using from whisperlivekit import get_inline_ui_html & page = get_inline_ui_html()
Parameters & Configuration
An important list of parameters can be changed. But what should you change?
- the
--modelsize. List and recommandations here - the
--language. List here. If you useauto, the model attempts to detect the language automatically, but it tends to bias towards English. - the
--backend? you can switch to--backend faster-whisperifsimulstreamingdoes not work correctly or if you prefer to avoid the dual-license requirements. --warmup-file, if you have one--host,--port,--ssl-certfile,--ssl-keyfile, if you set up a server--diarization, if you want to use it.
The rest I don’t recommend. But below are your options.
| Parameter | Description | Default |
|---|---|---|
--model |
Whisper model size. | small |
--language |
Source language code or auto |
auto |
--task |
transcribe or translate |
transcribe |
--backend |
Processing backend | simulstreaming |
--min-chunk-size |
Minimum audio chunk size (seconds) | 1.0 |
--no-vac |
Disable Voice Activity Controller | False |
--no-vad |
Disable Voice Activity Detection | False |
--warmup-file |
Audio file path for model warmup | jfk.wav |
--host |
Server host address | localhost |
--port |
Server port | 8000 |
--ssl-certfile |
Path to the SSL certificate file (for HTTPS support) | None |
--ssl-keyfile |
Path to the SSL private key file (for HTTPS support) | None |
| WhisperStreaming backend options | Description | Default |
|---|---|---|
--confidence-validation |
Use confidence scores for faster validation | False |
--buffer_trimming |
Buffer trimming strategy (sentence or segment) |
segment |
| SimulStreaming backend options | Description | Default |
|---|---|---|
--frame-threshold |
AlignAtt frame threshold (lower = faster, higher = more accurate) | 25 |
--beams |
Number of beams for beam search (1 = greedy decoding) | 1 |
--decoder |
Force decoder type (beam or greedy) |
auto |
--audio-max-len |
Maximum audio buffer length (seconds) | 30.0 |
--audio-min-len |
Minimum audio length to process (seconds) | 0.0 |
--cif-ckpt-path |
Path to CIF model for word boundary detection | None |
--never-fire |
Never truncate incomplete words | False |
--init-prompt |
Initial prompt for the model | None |
--static-init-prompt |
Static prompt that doesn’t scroll | None |
--max-context-tokens |
Maximum context tokens | None |
--model-path |
Direct path to .pt model file. Download it if not found | ./base.pt |
--preloaded-model-count |
Optional. Number of models to preload in memory to speed up loading (set up to the expected number of concurrent users) | 1 |
| Diarization options | Description | Default |
|---|---|---|
--diarization |
Enable speaker identification | False |
--diarization-backend |
diart or sortformer |
sortformer |
--segmentation-model |
Hugging Face model ID for Diart segmentation model. Available models | pyannote/segmentation-3.0 |
--embedding-model |
Hugging Face model ID for Diart embedding model. Available models | speechbrain/spkrec-ecapa-voxceleb |
For diarization using Diart, you need access to pyannote.audio models:
- Accept user conditions for the
pyannote/segmentationmodel- Accept user conditions for the
pyannote/segmentation-3.0model- Accept user conditions for the
pyannote/embeddingmodel- Login with HuggingFace:
huggingface-cli login
🚀 Deployment Guide
To deploy WhisperLiveKit in production:
-
Server Setup: Install production ASGI server & launch with multiple workers
1 2pip install uvicorn gunicorn gunicorn -k uvicorn.workers.UvicornWorker -w 4 your_app:app -
Frontend: Host your customized version of the
htmlexample & ensure WebSocket connection points correctly -
Nginx Configuration (recommended for production):
1 2 3 4 5 6 7 8 9server { listen 80; server_name your-domain.com; location / { proxy_pass http://localhost:8000; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; }} -
HTTPS Support: For secure deployments, use “wss://” instead of “ws://” in WebSocket URL
🐋 Docker
Deploy the application easily using Docker with GPU or CPU support.
Prerequisites
- Docker installed on your system
- For GPU support: NVIDIA Docker runtime installed
Quick Start
With GPU acceleration (recommended):
|
|
CPU only:
|
|
Advanced Usage
Custom configuration:
|
|
Memory Requirements
- Large models: Ensure your Docker runtime has sufficient memory allocated
Customization
--build-argOptions:EXTRAS="whisper-timestamped"- Add extras to the image’s installation (no spaces). Remember to set necessary container options!HF_PRECACHE_DIR="./.cache/"- Pre-load a model cache for faster first-time startHF_TKN_FILE="./token"- Add your Hugging Face Hub access token to download gated models
🔮 Use Cases
Capture discussions in real-time for meeting transcription, help hearing-impaired users follow conversations through accessibility tools, transcribe podcasts or videos automatically for content creation, transcribe support calls with speaker identification for customer service…